
Парсинг данных с n8n: от простых запросов до надёжной автоматизированной системы
Зачем бизнесу n8n‑парсинг и как работают базовые узлы
Представьте типичную картину: менеджер открывает десятки вкладок, вручную копирует цены конкурентов в Excel, а через два часа половина данных уже устарела. Или команда заказывает у разработчиков кастомный скрипт за приличные деньги — и он ломается через три недели после редизайна чужого сайта. Знакомо? Эта статья — практическое руководство, а не теория. Здесь вы узнаете, как решить эти проблемы конкретными инструментами.
Что вообще решает веб-скрапинг в бизнесе?
Сбор данных из открытых источников — это не хакерство, а обычная бизнес-операция. Вот только три самых распространённых сценария:
- Мониторинг цен конкурентов. Интернет-магазины и маркетплейсы отслеживают десятки тысяч позиций и автоматически корректируют собственные прайсы.
- Сбор лидов. Парсинг открытых каталогов, досок объявлений и профессиональных площадок — быстрый способ пополнить базу потенциальных клиентов.
- Агрегация новостей и контента. Медиа, аналитические агентства и корпоративные команды собирают отраслевую информацию из десятков источников в единый дашборд.
Почему n8n, а не кастомный скрипт?
Написать скрипт на Python или Node.js «с нуля» — значит тратить время на инфраструктуру, а не на бизнес-задачу. n8n — это low-code платформа автоматизации с визуальным редактором рабочих процессов. Настроить базовый n8n‑парсинг можно за 15 минут, не написав ни строчки кода. Плюс готовые интеграции с сотнями сервисов: Google Sheets, CRM, Telegram, базы данных — всё это подключается через drag-and-drop, а не через стек зависимостей.
Ещё одно ключевое преимущество: когда скрипт ломается, нужен разработчик. Когда ломается нода в n8n — схему правит любой аналитик или менее опытный технический специалист, просто глядя на визуальный граф.
Как работает парсинг сайта n8n на базовом уровне?
Для статических страниц, где весь HTML уже содержится в ответе сервера, достаточно двух стандартных нод:
- HTTP Request — отправляет GET-запрос на нужный URL и получает HTML-код страницы.
- HTML Extract — извлекает конкретные данные по CSS-селекторам (например, .price, h2.product-title, table tr td:nth-child(2)).
Эта связка отлично покрывает большинство новостных сайтов, лендингов, каталогов со старой архитектурой и открытых API, которые возвращают HTML. Вы указываете URL → получаете страницу → вырезаете нужные данные → передаёте их дальше по схеме.
Всё просто — до тех пор, пока вы не столкнётесь с сайтами нового поколения. Откройте инструменты разработчика в браузере на любом крупном маркетплейсе или SaaS-продукте, и вы увидите: HTML-ответ сервера — это почти пустая страница с одним тегом <div id="root"></div>. Весь контент генерируется JavaScript уже в браузере пользователя. Именно об этом — следующий блок.
Продвинутый парсер n8n — укрощение динамического контента
Представьте, что сайт — это не готовая книга, а конструктор LEGO в коробке. Сервер отправляет вам коробку с деталями (JavaScript, JSON, компоненты React или Vue), а собирает её в читаемую страницу уже браузер на компьютере пользователя. Когда HTTP Request обращается к такому сайту напрямую, он получает именно эту «коробку с деталями» — нечитаемый набор скриптов без единой строки полезного контента. Для таких сайтов нужен «виртуальный пользователь» — headless-браузер.
Что такое headless-браузер?
Headless-браузер — это полноценный браузерный движок (Chromium, Firefox), который работает без графического интерфейса, то есть «без головы». Он загружает страницу, выполняет весь JavaScript, ждёт появления нужных элементов в DOM — и только после этого отдаёт вам готовый, отрендеренный HTML. Для сайта-донора такой браузер выглядит как обычный посетитель.
Puppeteer vs Playwright в связке с n8n
Два самых популярных инструмента для управления headless-браузерами — это Puppeteer и Playwright. Оба интегрируются в n8n через ноду Execute Command или выделенный микросервис, который общается с n8n по webhook.
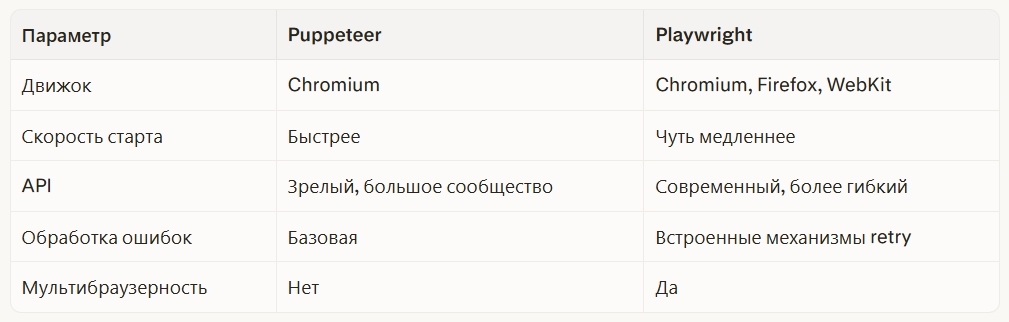
n8n + Puppeteer — проверенный выбор для Chromium-ориентированных задач: клик по кнопке «Показать ещё», скроллинг до конца страницы с бесконечной лентой, авторизация через форму логина с последующим сбором данных за аутентификацией.
n8n + Playwright — предпочтительный вариант, если нужна кроссбраузерность или встроенная устойчивость к нестабильным сетям. Playwright умеет автоматически ждать появления элемента в DOM перед кликом, что избавляет от ошибок типа «элемент не найден».
Практический пример сценария: n8n запускает webhook → Playwright открывает страницу каталога → прокручивает её до конца → кликает на каждую карточку товара → ждёт загрузки модального окна → извлекает цену, артикул, описание → возвращает JSON обратно в n8n для дальнейшей обработки.
Важно понимать: использование браузерных движков — это ресурсоёмкий процесс. Каждый запущенный экземпляр Chromium потребляет 200–400 МБ оперативной памяти. На больших объёмах это превращается в инфраструктурную задачу. Но даже идеально работающий парсер n8n — это лишь половина дела. Настоящий вызов начинается, когда сайт-донор замечает ваш скрапер и начинает ставить барьеры. О том, как их обойти и куда направить собранные данные — в следующем блоке.
Архитектура надёжной системы: обход блокировок и маршрутизация данных
Суровая правда веб-скрапинга: сайты активно защищаются. Cloudflare, капча, rate limiting, анализ поведенческих паттернов — если вы не продумаете архитектуру с самого начала, ваш IP будет заблокирован уже после первых сотен запросов. Хороший n8n‑парсинг — это не только «достать данные», но и сделать это незаметно, стабильно и в промышленных масштабах.
Как не попасть в бан: основные методы защиты
- Ротация прокси. Используйте пул резидентных или датацентровых прокси-серверов. В n8n это реализуется через переменные окружения или ноду HTTP Request с динамической подстановкой прокси из списка. Каждый запрос — новый IP.
- Смена User-Agent. Храните массив реальных строк User-Agent (Chrome, Firefox, Safari разных версий) и подставляйте случайный при каждом обращении.
- Задержки между запросами. Нода Wait с рандомизированным интервалом (например, от 2 до 8 секунд) имитирует человеческое поведение и снижает риск срабатывания rate limiter.
- Обход Cloudflare. Для сайтов за Cloudflare используются специализированные решения: сервисы типа ScraperAPI или ZenRows, которые самостоятельно обрабатывают JS-челлендж, либо браузерный fingerprinting через Playwright с кастомными профилями.
- Капча. Интегрируется через сторонние сервисы (2captcha, Anti-Captcha) — n8n отправляет изображение капчи через их API и получает решение обратно.
Пагинация и обработка ошибок
Парсинг сайта n8n редко ограничивается одной страницей. Для обхода пагинации используется петля (loop): нода IF проверяет наличие кнопки «Следующая страница» или увеличивает счётчик ?page=N — и возвращает управление в начало сценария до тех пор, пока страницы не закончатся.
Обработка ошибок строится через ноду Error Trigger и механизм Retry on Fail:
- Если сайт вернул 503 — подождать 60 секунд и повторить запрос.
- Если структура страницы изменилась и данные не извлеклись — отправить уведомление в Telegram или на email и пометить задачу как «требует проверки».
- Если прокси недоступен — взять следующий из пула.
Куда направлять собранные данные
n8n имеет нативные интеграции с десятками систем хранения:
- Google Sheets / Airtable — для команд, которым нужен простой визуальный доступ к данным.
- CRM (HubSpot, Bitrix24, AmoCRM) — лиды из парсера попадают прямо в воронку продаж как контакты или сделки.
- PostgreSQL / MySQL — для больших объёмов и сложной аналитики.
- Webhook в собственный сервис — для команд с собственной инфраструктурой.
Представьте: каждые два часа система автоматически обходит 500 страниц каталога конкурента, очищает данные от мусора, сравнивает с вашими ценами, и — если разница превысила 5% — создаёт задачу менеджеру в CRM с конкретным артикулом и рекомендацией. Без единого человека в цепочке. Именно так работает промышленный n8n‑парсинг. И именно такую систему хочет каждый бизнес, который хоть раз считал, сколько часов в неделю уходит на ручной сбор данных. Но прежде чем бросаться строить её самостоятельно — честно оцените скрытые расходы.
Поддержка скраперов и конверсионный оффер: когда строить самому, а когда делегировать
n8n даёт потрясающие возможности для парсинга — это факт. Но за красивым визуальным интерфейсом скрывается серьёзная техническая глубина: понимание сетевых протоколов, DOM-структуры, методов обхода защит, инфраструктуры хостинга и принципов отказоустойчивости. Компании, которые недооценивают этот факт, обычно проходят один и тот же путь.
Скрытые расходы самостоятельной поддержки
Самая большая иллюзия — «запустил и забыл». На практике парсер n8n требует регулярного обслуживания:
- Изменение вёрстки сайта-донора. Конкурент обновил дизайн — и все ваши CSS-селекторы перестали работать. Это происходит без предупреждения, в любой день. Кто-то должен мониторить ошибки и чинить схему.
- Смена антибот-политики. Сайт подключил новый уровень защиты Cloudflare или добавил капчу — вся цепочка останавливается.
- Падение прокси-провайдера. Нужен резервный пул и логика автопереключения.
- Рост объёмов. То, что работало для 100 страниц в день, не масштабируется на 10 000 без перепроектирования архитектуры.
- Инфраструктурные расходы. Сервер для n8n, оплата прокси, антикапча-сервисы, мониторинг — всё это деньги и время DevOps-специалиста.
В итоге «бесплатный» инструмент превращается в полноценную внутреннюю разработку со своим стеком поддержки.
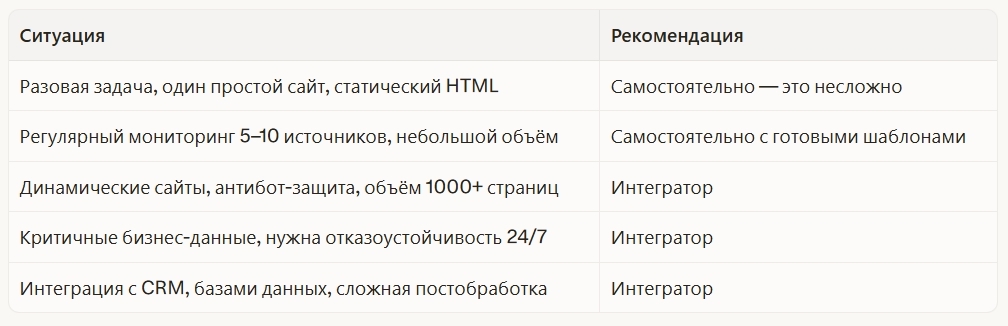
Когда строить самому, а когда заказывать у интегратора?
Как мы помогаем
Мы — команда интеграторов, которая специализируется на построении автоматизированных систем на базе n8n. Наш подход: не просто настроить парсер, а спроектировать всю цепочку — от источника данных до конечного действия в вашем бизнес-процессе.
Что входит в нашу работу:
- Аудит источников данных и выбор оптимальной архитектуры (статика / headless / API)
- Настройка ротации прокси и обхода защит под конкретные сайты
- Подключение к вашей CRM, базе данных или Google Sheets
- Настройка мониторинга и автоматических уведомлений при сбоях
- Документация и передача схемы вашей команде
Не тратьте часы разработчиков на метод проб и ошибок.
Каждый час, который ваша команда тратит на отладку сломанного парсера — это час, не потраченный на рост бизнеса. Мы уже прошли этот путь за десятки клиентов и знаем, где именно ломаются 90% самостоятельных решений.
Запишитесь на бесплатную консультацию — разберём вашу задачу, покажем, как будет выглядеть готовая система, и дадим честную оценку сроков и стоимости внедрения.
👉 Оставьте заявку на консультацию — ответим в течение одного рабочего дня.
